Randomisierte Algorithmen
Eine Zusammenfassung von randomisierten Algorithmen, in Form eines Blogposts.
Target-Shooting
:= Covid-Geimpfte Bevölkerung
:= Schweizer Bevölkerung
Welcher Prozentsatz der Schweizer Bevölkerung ist geimpft?
=> eine Approximation für gesucht
Idee: Elemente aus U auswählen und dann den daraus den Anteil der Elemente aus bestimmen. Dafür müssen die Elemente aus zufällig, gleichverteilt und unabhängig gewählt sein.
Wie man wählen muss, um eine Erfolgs-/Fehlerwahrscheinlichkeit zu erreichen, steht in der Formelsammlung. Wir stellen in der Formel für fest, die Fehlerwahrscheinlichkeit geht nur logarithmisch ein.
:= gewünschte maximale Fehlerwahrscheinlichkeit
:= maximal akzeptable Abweichung damit mit Wahrscheinlichkeit 1- die Approximation innerhalb der Abweichung liegt
Duplikate finden
Gegeben sei ein Datensatz mit Elementen. Nun müssen wir alle Duplikate (identische Elemente) in diesem Datensatz finden.
1. Ansatz: Sortiere die Elemente und durchlaufe die sortierte Folge, nur aufeinanderfolgende Elemente können potentiell Duplikate voneinander sein. Dies kostet für das Sortieren und für das anschliessende durchlaufen.
Da Speicherzugriffe sowie Vergleiche als sehr teuer anzunehmen sind, da Elemente aus gross sind, suchen wir einen sparsameren Ansatz.
2. Ansatz: Wir verwenden eine Hashfunktion welche effizient berechenbar ist und sich zufällig verhält. Wir bilden eine grössere Eingabemenge (wovon eine Teilmenge ist), auf eine kleinere Zielmenge, die Hashwerte, ab. Die Hashwerte sollen zufällig gleichverteilt auftreten, und es gilt
Um Duplikate zu finden, hashen wir nun zuerst den Datensatz, dann sortieren wir nach Hashwert, durchlaufen anschliessend die sortierten Hashwerte um Duplikate zu finden und für Kollisionen zu prüfen. Das alles ist viel günstiger, denn die Zielmenge der Hashfunktion ist viel kleiner als die Eingabemenge, also sparen wir uns die teueren Speicherzugriffe sowie Vergleiche, welche im 1. Ansatz ein Problem darstellten.
Kollisionen sind Elemente welchen den gleichen Hashwert zugeschrieben werden, welche aber keine Duplikate voneinander sind. Sei die Anzahl der Hashwerte die möglich sind. Was ist die W’keit das zwei beliebige Elemente eine Kollision darstellen?
Da wir Paare von Elementen aus ziehen können, und tatsächliche Duplikate nicht als Kollisionen zählen, können wir eine obere Schranke für die Anzahl Kollisionen wie folgt abschätzen (wenn es keine Duplikate gibt dann gilt sogar anstatt )
Laufzeit: für die Hashmap + für das Sortieren von + für das Durchlaufen, sowie Speicher ( für die Indizes und für die Hashwerte)
Bloom Filter: Hashfunktionen kombiniert in ein Hash-Tuple, Sammeln von Wiederholungen in einer Liste
Ergebnis "keine Duplikate" immer korrekt, Ergebnis "Duplikat gefunden" nicht immer korrekt
Primzahltest
Gesucht: Ist die Zahl prim?
Euklidisch
:= Zufallszahl zwischen und
Ausgabe "nicht Prim" immer korrekt, Ausgabe "Prim" falsch mit Wahrscheinlichkeit
Fermat
:= Zufallszahl zwischen und
Ausgabe "nicht Prim" immer korrekt, Ausgabe "Prim" falsch mit Wahrscheinlichkeit ausser wenn n eine Carmichael Zahl ist
Charmichael Zahl: ist nicht prim und für alle a gibt der Fermattest fälschlicherweise Prim aus
Miller Rabin
:= Zufallszahl zwischen und
Wenn gilt:
- exponent durch teilen bis ungerade oder es nicht oder ist
Ausgabe "nicht Prim" immer korrekt, Ausgabe "Prim" falsch mit Wahrscheinlichkeit
Randomisiertes Quicksort
Indem wir unser Pivotelement zufällig wählen, können wir verhindern dass bestimmte Inputs ein worst-case Szenario ergeben. Wir interessieren uns für die erwartete Laufzeit, und hoffen diese für alle Eingaben möglichst zu verringern.
Wenn das Anfangs-Zahlenarray zufällig angeordnet ist, dann hat ein standardmässiges Quicksort genauso viele erwartete Vergleiche wie das randomisierte Quicksort. Merke: wenn Elemente nicht alle einzigartig sind, dann stimmt die Schranke nicht mehr (wegen Abhängigkeit von Zufallsvariablen)
Quickselect
Random Pivot wählen und so ein Element suchen.
Suchbaum
Randomisiertes Quicksort baut implizit einen zufälligen Suchbaum auf, wobei das erste Pivot die Wurzel des Baums ist, das linke Kind der Wurzel ist das Pivot der linken Teilhälfte, usw.
Die tiefe eines Elements im Baum ist dabei gleich der Anzahl Vergleiche mit dem Element als Nichtpivot im Quicksort.
Lange Pfade
Enthält ein Graph einen Pfad der Länge ? Ein Pfad der Länge hat Kanten und Knoten.
Dieses Problem ist NP-Vollständig (vermutlich).
Wenn klein ist, genauer gesagt , dann können wir das Problem in polynomieller Zeit mit DP lösen. Dazu führen wir das Bunte Pfade Problem ein.
Bunte Pfade
Sei eine natürliche Zahl. Sei ein Graph mit einer nicht notwendigerweise gültige Färbung
Gibt es einen bunten Pfad der Länge (d.h. mit K Knoten)? Gib es einen Pfad der Länge wobei alle Knoten im Pfad paarweise verschiedene Farben haben? Wir definieren

Bemerke, dass ein bunter Pfad der Länge zu aus einem -freien bunten Pfad der Länge zu einem Nachbarn von plus der Kante zu besteht. So können wir mithilfe von langen bunten Pfaden, bunte Pfade der Länge konstruieren. Wenn wir mit allen möglichen Pfaden der Länge anfangen ( viele), dann können wir für jeden solchen Pfad alle Pfade konstruieren die um länger sind, und somit aufbauend alle Pfade der Länge konstruieren.
Kehren wir nun zu unserem ursprünglichen Problem zurück. Um herauszufinden ob unser Graph einen Pfad der Länge enthält, färben wir unseren Graph zufällig mit Farben, und suchen nach einem bunten Pfad der Länge (mit Knoten). Wenn G einen solchen bunten Pfad mit Knoten enthält, dann ist die Wahrscheinlichkeit das unser Algorithmus, mit einer zufälligen Färbung, einen solchen findet, . Somit beträgt die erwartete Anzahl Versuche bis man einen solchen bunten Pfad findet , wegen der Geometrischen Verteilung mit Parameter .
Laufzeit
Ein Versuch dauert , und damit wir eine Fehlerwahrscheinlichkeit von haben, wiederholen wir den Algorithmus Mal.
Der bunte Pfade Algorithmus an sich läuft für in polynomialer Laufzeit, genauer gesagt für in .
DAGs
Alle Kanten mit gewichten und dann den kürzesten Pfad berechnen mit Bellman-Ford. Das Resultat ist der längste Pfad.
Mincut
Kardinalität eines kleinstmöglichen Kantenschnitts in
In einer Kantenkontraktion einer Kante verschmelzen wir die beiden inzidenten Knoten zu einem Knoten.

Es gilt: , bzw. Im Allgemeinen kann durch Kontraktion nie fallen, und bleibt gleich falls es einen minimalen Schnitt ohne gibt. Wir wollen herausfinden, also wollen wir die Kanten kontrahieren, welche nicht in einem minimalen Schnitt sind.
Falls es einen minimalen Schnitt gibt, aus dem nie eine Kante kontrahiert wird (per Zufall), so gibt der folgende Algorithmus tatsächlich aus
1während der Graph mehr als 2 Knoten hat:2kontrahiere eine zufällige Kante3return Grösse des eindeutigen Schnitts
Die Idee ist nun, den Zufallsalgorithmus so oft zu wiederholen, sodass er mit einer hohen Wahrscheinlichkeit tatsächlich ausgibt. Sei die Wahrscheinlichkeit das der Algorithmus ausgibt
Somit müssen wir erwartet höchstens Mal den Algorithmus wiederholen bis wir das erste Mal ausgeben.
Laufzeit
Für -malige Wiederholung hat der ganze Algorithmus eine Laufzeit von und die Erfolgswahrscheinlichkeit ist resp. die Fehlerwahrscheinlichkeit ist . Somit haben wir mit einen Algorithmus mit Fehlerwahrscheinlichkeit
Bootstrapping
Mit bootstrapping können wir unseren randomisieren Algorithmus um ein Vielfaches verbessern. Merke das in den letzten paar Schritten die Wahrscheinlichkeit eine im mincut enthaltene Kante zu kontrahieren, und somit ein zu hohes/fehlerhaftes Resultat zurückzugeben, sehr hoch ist. Im Allgemeinen steigt die Wahrscheinlichkeit eine "falsche" Kante zu kontrahieren mit jeder "korrekt" kontrahierten Kante an, somit haben wir in den letzten Schritten eine immens hohe Fehlerwahrscheinlichkeit.
Um dies zu umgehen wenden wir unseren langsamen, deterministischen Algorithmus genau für die wenigen letzten Schritte an, wo unsere Fehlerwahrscheinlichkeit so gross ist. Das kann man als Strategiewechsel im kritischen Bereich bezeichnen. Wann genau dieser Strategiewechsel am besten eintreten soll, um insgesamte Laufzeit und Erfolgswahrscheinlichkeit zu optimieren, kann kalibriert werden. Mit ist der Algorithmus statt nur noch . Dies ist eine 1-fache Anwendung von Bootstrapping. Nun bietet es sich an, auf diesen verschnellerten Algorithmus noch einmal Bootstrapping anzuwenden. Im "Limit", sprich mit "unendlich" wiederholtem bootstrapping, haben wir einen -Algorithmus, mit der gleichen Erfolgswahrscheinlichkeit wie der ursprüngliche Algorithmus.
Kleinster umschliessender Kreis
Gegeben eine engliche Punktemenge, finden wir den Kreis mit kleinstem Radius, der die Punktemenge umschliesst. Dieser Kreis für eine beliebige Punktemenge ist immer eindeutig, sprich es gibt keine Punktemenge wofür es zwei unterschiedliche kleinste umschliessende Kreise gibt. Auch ist bekannt, das dieser kleinste umschliessende Kreis von drei "äussersten" Punkten eindeutig definiert wird. Somit haben wir unseren deterministischen Algorithmus
x1Iteriere durch alle möglichen 3-Tupel von Punkten2C(Q) <- Bilde den kleinsten umschliessenden Kreis von diesen 3 Punkten3wenn C(Q) alle Punkte umschliesst:4return C(Q) ist der kleinste umschliessende Kreis der Punktemenge
Dieser Algorithmus läuft in . Wir können ihn verbessern, indem wir mit dem Radius arbeiten und so auf eine schlauere Weise die if-Bedingung statt kostet Algorithmus.
Nun wollen wir einen randomisierten Las-Vegas Algorithmus betrachten, welcher auch das korrekte Ergebnis ausgibt und im Erwartungswert schneller läuft. Dazu wählen wir 3 Punkte zufällig - und falls dies nicht der kleinste umschliessende Kreis ist - geben wir den Punkten ausserhalb dieses Kreises eine höhere Chance gewählt zu werden, indem wir die Punktemenge ausserhalb des Kreises verdoppeln. Je öfter wir zufällig 3 Punkte ziehen, desto eher werden wir Punkte wählen, welche weit aussen sind, bzw. je weiter aussen ein Punkt ist, desto öfter soll dieser tendenziell gewählt werden. Dies ist recht effektiv, denn die "äussersten" 3 Punkte spannen den kleinsten umschliessenden Kreis - wobei "äusserst" natürlich etwas arbiträr ist.
Analyse
Wir können jede Runde dieses randomisierten Algorithmus in Zeit implementieren. Die genaue Analyse für die Anzahl Runden ist kompliziert und kann auf den Slides (Lecture 23) angeschaut werden, doch wir haben Wiederholungen (im Erwartungswert) und somit da jede Wiederholung/Runde kostet, hat der randomisierte Algorithmus eine erwartete Laufzeit von .
Höhrere Dimensionen
In Dimensionen braucht es Punkte, um einen Kreis/Kugel/... in der respektiven Dimension eindeutig definieren zu können. Somit lässt sich dieser Algorithmus auch auf weitere Dimensionen erweitern.
Konvexe Hülle
Ist zwar kein randomisierter Algorithmus, aber dafür noch interessant
Eine konvexe Hülle einer Punktemenge , bezeichnet als , ist der Schnitt aller konvexen Mengen, die enthalten. In verständlichen Worten: eine konvexe Hülle sind Liniensegmente welche eine Punktemenge umranden, und zwar so, dass das resultierende Polygon konvex und kleinstmöglich ist. Die Ecken des Polygons sind Punkte der Menge, und das Polygon "umrandet" alle Punkte der Menge.
Wir gehen davon aus, keine 3 Punkte liegen auf einer Geraden und alle Punkte haben verschiedene -Koordinaten.
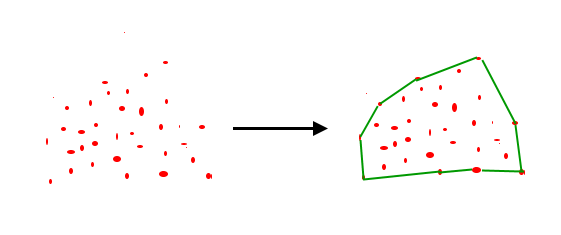
Jarvis Wrap
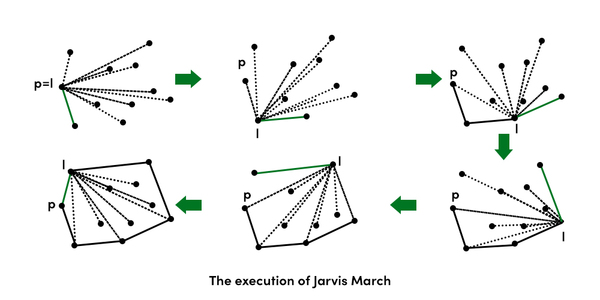
Wir fangen an mit dem Punkt mit der kleinsten -Koordinate, und suchen einen Punkt , sodass alle anderen Punkte links von der Geraden zwischen und liegen. Wegen unseren vereinfachenden Annahmen, gibt es einen solchen Punkt immer. Solch ein Schritt des Jarvis Wrap kostet , denn wir iterieren durch viele Punkte, bis wir einen finden, wozu die Gerade zwischen und eine Randkante ist. Wie die Relation "ist links von" ermittelt wird, hat etwas mit LinAlg und Determinanten zu tun - ptsd. Wir müssen unseren Jarvis-Wrap Schritt genauso oft ausführen, wie es Kanten in der konvexen Hülle gibt, denn pro Schritt finden wir genau eine neue Kante der Hülle. Somit haben wir die Laufzeit
LocalRepair
Wir sortieren die Punktemenge aufsteigend nach x-Koordinate. Nun verdoppeln wir das Polygon und fügen die verdoppelten Kanten invertiert in die Polygonmenge . Nun konvexifizieren wir dieses Polygon

Wir entfernen einen Punkt falls er links von der Geraden liegt. Führen wir dies aus, so konvexifizieren wir das Polygon und erhalten am Schluss die konvexe Hülle sowie eine Triangulierung der Punkte, dessen Umriss die konvexe Hülle ergibt.

Der Algorithmus läuft in , wobei das Sortieren kostet und das konvexifizieren bloss . Also wenn die Punkte bereits in sortierter Reihenfolge gegeben sind, dann braucht LocalRepair Zeit.
Konvexe Mengen

~Tobi